
Industrial data has always been difficult to work with. Digitally integrating business processes, in the pursuit of productivity, may be making it more so. As organizations connect more systems in more directions, the demands placed on that data multiply with every integration.
The gap between what existing systems were built for and what organizations need today is real. Data distributed across areas, sites, and networks is difficult to contextualize and access as a unified whole. And as deployments expand and more teams get involved, the knowledge behind data pipelines needs to be more accessible, not just to the engineers who originally built them, but to the broader teams who work with and support them every day.
HighByte Intelligence Hub version 4.4 is built for exactly that environment. This release introduces Central Data for composing federated namespaces and pipelines with remote data sources, new connectivity options including native Databricks Zerobus support and the CESMII i3X Server interface, and a Pipeline AI Agent that makes pipeline configuration more accessible across teams and skill levels. Taken together, they extend what Industrial DataOps teams can do and who can do it.
This post walks through each capability and what it makes possible.
Central Data: A Federated Data Plane Across Systems and Networks
Industrial data does not originate or live in one place. It is distributed across sites, areas, systems, and networks. Yet the applications, services, and users that depend on it need access to it as if it were in one place. Industrial organizations want to model, contextualize, and flow their data holistically. The distributed nature of that data makes it difficult to do so in a unified, manageable way.
To address this, version 4.4 introduces Central Data along with a new internal subscription mechanism.
Central Data
Since version 3.0, the Intelligence Hub has included Central Configuration, providing the ability to securely connect remote hubs to a central hub and manage their configuration. Since the introduction of Namespaces in version 4.0, users have asked for ways to federate namespaces from remote hubs into a central hub. Version 4.4 addresses this with Central Data.
Central Data extends the concept of Central Configuration by exposing the data plane of one hub to a central hub. Once connected, the central hub can see the namespace of each remote hub and map its nodes into a central namespace. Users can browse that namespace, run Smart Queries, and build Pipelines that subscribe to and draw from remote data sources as if they were local.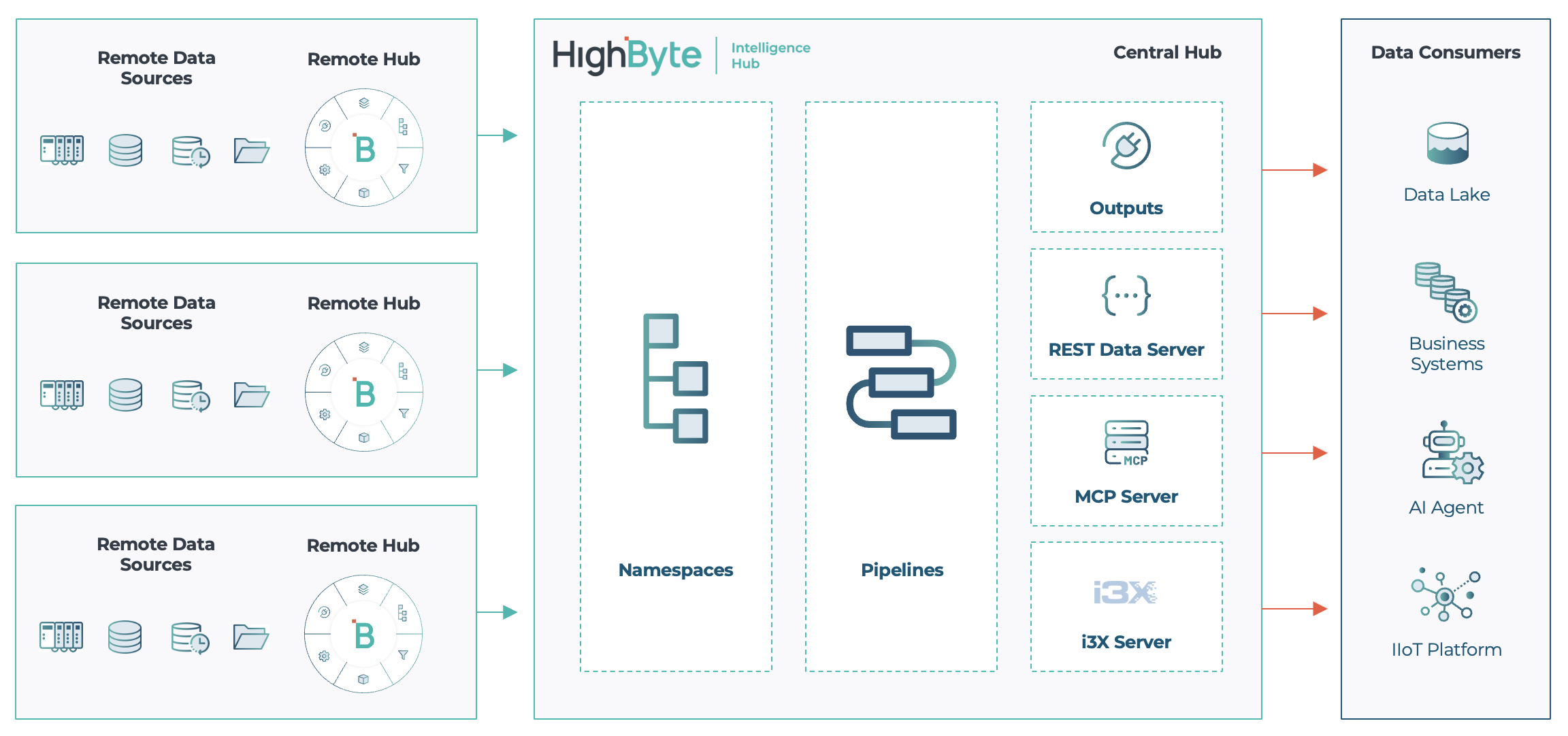
Central Data in HighByte Intelligence Hub version 4.4
To make this concrete: A single Pipeline can execute a Smart Query across contextualized datasets from multiple remote hubs, subscribe to relevant readings for condition-based maintenance, shape the data to match the MaintainX API, and publish directly to MaintainX—all from a single hub serving on behalf of many distributed data sources across network boundaries.
Central Data simplifies distributed architectures, enabling a common set of pipelines to serve enterprise data targets from a single hub, with all modeled factory data discoverable and actionable on demand.
Internal Subscriptions
The Intelligence Hub has supported subscribing to eventful sources like OPC UA and MQTT since its first release. However, as data models and data pipelines grow more sophisticated, so does the need to subscribe to changes across complex objects like Model-Instances, which may be composed of both event-driven and non-event-driven sources.
Version 4.4 introduces subscription support for complex objects including Instances, Namespaces, and OPC UA Branches and Collections. Using new pipeline triggers, events are automatically generated when the underlying source data changes. For example, if an Instance is composed of OPC UA tags and SQL data, an event is created when the OPC tags change and the payload includes the latest values pulled from SQL. Subscriptions also work on namespaces, including nodes federated through Central Data, generating events for the pipeline when node values change.
This new capability simplifies pipeline design, eliminates the need to poll for changes, and ensures data changes are never missed across both local and distributed data sources.
Advancing Connectivity for Industry
The industrial data landscape is shaped by the key platforms organizations have invested in and the open standards that define how systems connect. Depth of integration with those platforms, from bulk and streaming ingestion to query and agentic access, is what separates surface-level connectivity from real impact.
Open standards are equally important, reducing the undifferentiated heavy lifting and total cost of ownership for all involved.
Leadership in connectivity means staying ahead on both fronts, supporting the platforms where work gets done and fostering open standards that translate into real-world adoption. Version 4.4 does both.
Databricks Zerobus
Databricks has become one of the most widely adopted platforms for analytics and AI workloads, and the Intelligence Hub has built comprehensive integration across the full spectrum of interaction patterns. For ingest, the Intelligence Hub supports bulk loading via object storage and direct bulk via the Databricks Storage connection. For query and reverse ETL, the Databricks SQL connection enables direct access from Databricks back to OT systems. Streaming ingest has also been supported, but previously required routing data through an intermediate event streaming service such as Amazon Kinesis Data Streams, Azure Event Hubs, or Apache Kafka before reaching Databricks.
Databricks Zerobus changes that. It is a new, serverless streaming ingestion interface that enables record-by-record data ingestion directly into Delta tables. Version 4.4 introduces a native Zerobus connection in the Intelligence Hub, enabling direct, low-latency streaming ingest into Databricks without any intermediate service. Tables are created and schemas evolved automatically based on model definitions. Data lands directly in Delta Lake and is immediately visible in Unity Catalog.
Direct Databricks integrations in HighByte Intelligence Hub version 4.4
With the new Databricks Zerobus connection, the Intelligence Hub now covers the full spectrum of direct Databricks integration, from bulk and streaming ingest to query.
i3X Server
Industrial connectivity standards have largely focused on telemetry and process control. For the broader set of interactions that applications need, including browsing, transactional reads and writes, and historical queries, the landscape is fragmented. Where standards exist, adoption has been inconsistent. In practice, every vendor implements a standard differently. Every integration requires custom work, and that burden multiplies as the number of applications grows. The Industrial Information Interoperability eXchange (i3X) addresses this by defining a common, app-centric API that covers all these interaction patterns.
The i3X specification is being developed through CESMII, with participation from leading industrial software vendors, system integrators, and end users. HighByte is an active contributor to the specification, and version 4.4 of the Intelligence Hub introduces an early implementation of the i3X Server interface, making the Intelligence Hub one of the first products to ship with i3X support.
The i3X Server exposes the Intelligence Hub namespace, including both the internal HighByte namespace and user-defined models, to any i3X-compatible client. Clients can browse, read, and subscribe to namespace nodes through a standard interface. The i3X Server reflects the Intelligence Hub's API-centric approach to Industrial DataOps, extending its standard server interfaces alongside the REST Data Server and MCP Server. As the i3X specification moves toward finalization, the Intelligence Hub's implementation will be updated to the official v1.0 release.
Pipeline AI Agent
Pipelines are at the core of the Intelligence Hub, controlling how data moves and how it is processed. For teams early in their Industrial DataOps journey, there is a learning curve to understanding how to configure them. As deployments grow and more teams get involved, that configuration needs to be understood, maintained, and handed off to people who may not have built it themselves.
Version 4.4 addresses this with the new Pipeline AI Agent, an in-app agent that connects to the user's LLM of choice and lets them conversationally summarize, create, and edit Pipeline configuration. Once the agent proposes changes, the Pipeline UI displays exactly what was added or modified. Users can debug and test the changes, then accept or reject them and continue iterating.
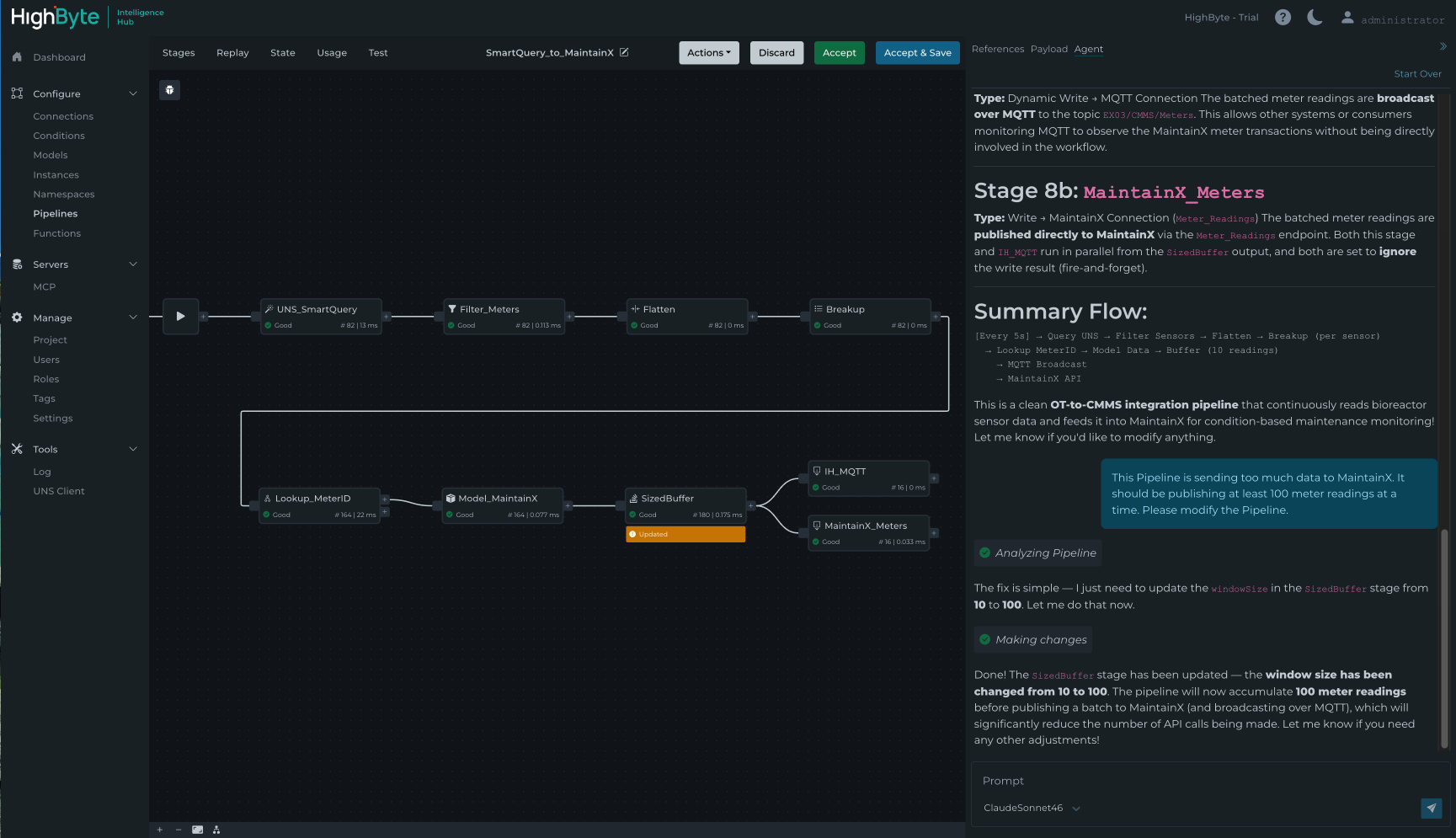
Pipeline AI Agent in HighByte Intelligence Hub version 4.4
A few examples of what that looks like in practice:
-
"I'm debugging a Pipeline someone else built. I’m not familiar with it. Explain what this Pipeline does and walk me through each stage."
-
"I need to create a data flow that subscribes to the boiler topic, queues 100 data changes, converts them to parquet format, and uploads the file to Azure Blob Storage using the current timestamp."
The Pipeline AI Agent makes sophisticated Pipeline configuration more accessible across teams and skill levels, with human discretion in the loop at every step.
Looking Ahead
HighByte Intelligence Hub version 4.4 advances Industrial DataOps on three fronts. Central Data and internal subscriptions simplify how distributed industrial data is managed and made available across the enterprise. Native Databricks Zerobus support and the i3X Server deepen the Intelligence Hub's integration with the platforms and standards that matter most. And the Pipeline AI Agent makes Pipeline configuration more accessible to every member of the team.
Beyond the features highlighted here, version 4.4 includes performance improvements, enhancements to Pipelines and Store & Forward, and new capabilities across Snowflake, AVEVA PI System, Oracle Database, OPC UA, Sparkplug, and AWS connections.
To learn more:
- Read the product announcement
- Explore the release notes for details on all new features and fixes
- Request a free trial or log in to your existing account to get started
