
I consistently hear that many manufacturers are drowning in data and struggling to make it useful. Why is that?
A modern industrial facility can easily produce more than a terabyte of data each day. With a wave of new technologies for artificial intelligence and machine learning coupled with real-time dashboards and prescriptive insights, industrial companies should be seeing huge gains in productivity. Unplanned asset and production line maintenance should be a thing of the past. But we know that is not the case.
Access to data does not make it useful. Industrial data is raw and must be made fit for purpose to extract its true value. Furthermore, the tools used to make the data fit for purpose must operate at the scale of an industrial enterprise. For many industrial companies, this is a daunting task requiring alignment of people, process, and technology across a global footprint and supply chain.
At HighByte, we’re putting our best foot forward to solve this data architecture and contextualization problem from a technology perspective. But what about people and process? To pull it all together, we recently published a new guide, “Think Big, Start Small, Scale Fast: The Data Engineering Workbook.” The guide provides 10 steps to achieving a scalable data architecture based on the best practices we’ve learned from our customers over the last several years.
A modern industrial facility can easily produce more than a terabyte of data each day. With a wave of new technologies for artificial intelligence and machine learning coupled with real-time dashboards and prescriptive insights, industrial companies should be seeing huge gains in productivity. Unplanned asset and production line maintenance should be a thing of the past. But we know that is not the case.
Access to data does not make it useful. Industrial data is raw and must be made fit for purpose to extract its true value. Furthermore, the tools used to make the data fit for purpose must operate at the scale of an industrial enterprise. For many industrial companies, this is a daunting task requiring alignment of people, process, and technology across a global footprint and supply chain.
At HighByte, we’re putting our best foot forward to solve this data architecture and contextualization problem from a technology perspective. But what about people and process? To pull it all together, we recently published a new guide, “Think Big, Start Small, Scale Fast: The Data Engineering Workbook.” The guide provides 10 steps to achieving a scalable data architecture based on the best practices we’ve learned from our customers over the last several years.
Step 1. Think big: Align your goals with the organization.
As with any major initiative, ensuring that your project is aligned with corporate goals must be the first step. Make sure the right cross-functional stakeholders are in the room from the project beginning, and that all stakeholders agree to prioritize the project and can reach consensus on the project goals.
Step 2. Get strategic: Consider your architectural approach.
Lack of architectural strategy is one of the most common sources of failure for Industry 4.0 initiatives. Taking the time to plan your architecture before you start your project pays dividends as you expand to other areas and sites. A well-planned data architecture will deliver the visibility and accessibility necessary to give your people and systems the data they need when they need it. Document how your systems are currently integrated and how this architecture may need to change to accomplish your project and corporate goals.
Step 3. Start small: Begin with a use case.
Your use case may be driven by assets, processes, or products. Regardless, company stakeholders should identify the project scope, applicable data that will be required, and the target persona who will consume this information and act on it. Use cases range from predictive asset maintenance to first-pass yield to enterprise OEE and more. This first use case is how you will prove value and return on investment.
Step 4. Identify The Target Systems.
This approach is contrary to traditional data acquisition approaches that would have you begin with source systems. Focusing on your target systems first will allow you to identify exactly what data you need to send, how it must be sent, and at what frequency it should be sent so you can determine which sources and structure are best suited to deliver that data. Focusing on the target system and persona will also help identify the context the data may require and the frequency of the data updates.
Step 5. Identify the data sources.
You can better understand the specific challenges you will need to overcome for your project by documenting your data sources. These challenges may include data volume, correlation, context, and standardization. Document data sources and their nuances now to prevent future obstacles to success.
Step 6. Select the integration architecture.
This is the step where an Industrial DataOps solution like HighByte Intelligence Hub should be evaluated. A DataOps solution acts as an abstraction layer that uses APIs to connect to other applications while providing a management, documentation, and governance tool that connects data sources to all required applications. DataOps solutions should be purpose-built to move high volumes of data at high speeds with transformations being performed in real time while the data is in motion. As your use case scales, your DataOps solution should easily scale with it.
Step 7. Establish Secure Connections.
Once your project plan is in place, you can begin system integration in earnest by establishing secure connections to source and target systems. It is vital that you wholly understand the protocols you will be working with and the security risks and benefits that come with them. Security is not just about usernames, passwords, encryption, and authentication. It is also about protocol selection and integration architecture.
Step 8. Model The Data.
The first step in modeling data is to define the standard data set required in the target system to meet the project’s business goals. The real-time data coming off the machinery and automation equipment is typically at the core of the model. These models should also include attributes for any descriptive data, which are not typically stored in industrial devices but are especially useful when matching and evaluating data in target systems. Models may also include data from transactional systems and time series databases. Once the standard models are created, they should be instantiated for each asset, process, and/or product relevant to the use case. This task can be accelerated with a DataOps solution like HighByte Intelligence Hub.
Step 9. Flow The Data.
When the instances are complete, data flows control the timing of when the values for an instance are sourced, standardized, contextualized, calculated, and sent to the target system. Data payloads may be published cyclically, when an event occurs, or only when a change occurs. A well-built data flow will retain the semantics of a model while transforming the presentation and delivery to the unique needs of the systems consuming it.
Step 10. Chart Your Progress and Expand to New Areas.
Now that your use case is officially off the ground, it is vital that you pay close attention to your results and track your progress. New Industry 4.0 use cases often explore entirely new functionality, so processes to track your progress may not presently exist in your organization. You may need to be the pioneer! Thankfully, product vendors like HighByte and outside service partners can help you.
Final Thoughts
Data engineering is essential to making your industrial data fit for purpose to extract its true value. Conceptually, we see data engineering as a process within Industrial DataOps (see Figure 1).
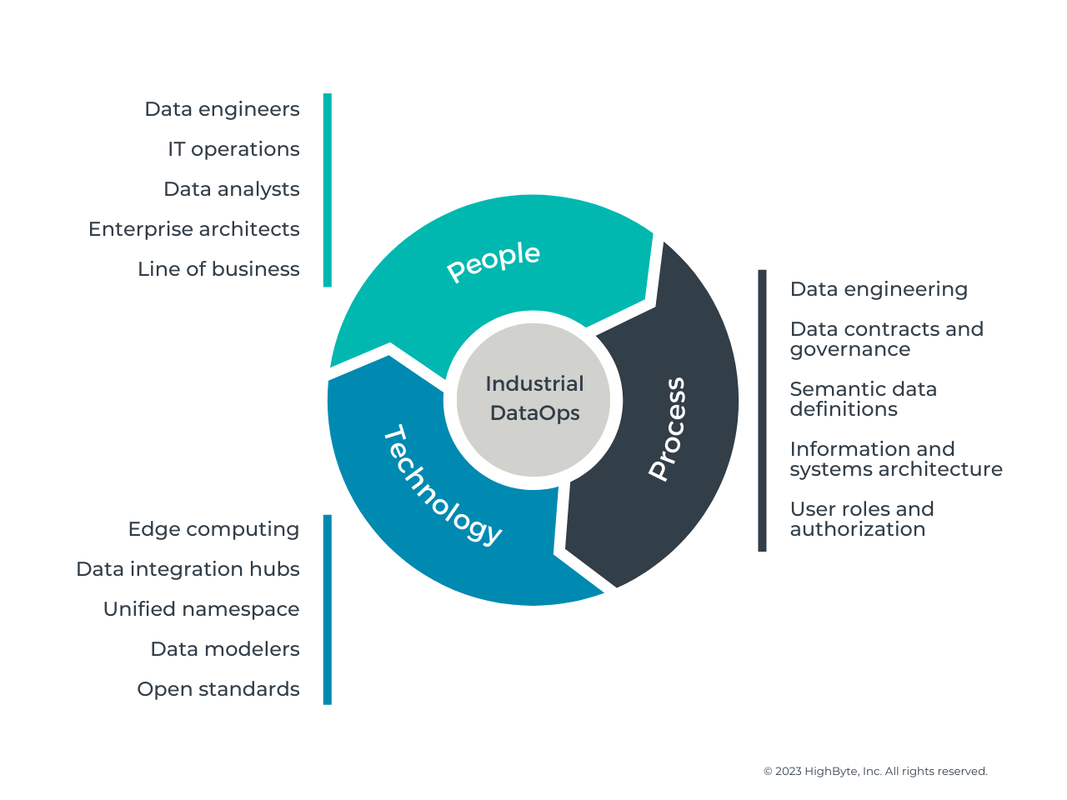
Figure 1: Industrial DataOps (data operations) is the orchestration of people, processes, and technology to securely deliver trusted, ready-to-use data to all the systems and people who require it.
Data engineering enables you to perform actions on your data, like standardizing, normalizing, transforming, filtering, and synchronization. To learn how to apply proven data engineering processes and technologies to your own work and go deeper into the 10 steps above, I recommend you download the complete workbook. Inside you’ll find:
Have questions? We’re here to help. Let’s take the first step and get started together.
- Detailed, 10-step guidance for your next project
- Short questionnaires for each step
- Best practices for ensuring secure connections, modeling data, and landing data in target systems
- A decision tree to help you select the right integration architecture for your business
Have questions? We’re here to help. Let’s take the first step and get started together.
