
In an earlier blog, “The power of payloads in your unified namespace,” I discussed the use of complex payloads combining multiple unified namespace (UNS) data streams to make the architecture more responsive to the diverse needs of consuming personas and systems. In this post, I want to show what these complex payloads might look like, how data models can enable a UNS architecture, and how easily HighByte Intelligence Hub can provide consuming systems with the necessary data—when and how it’s needed.
UNS Architecture
If you’re adhering to the ISA-95 hierarchy, your UNS probably looks something like this:
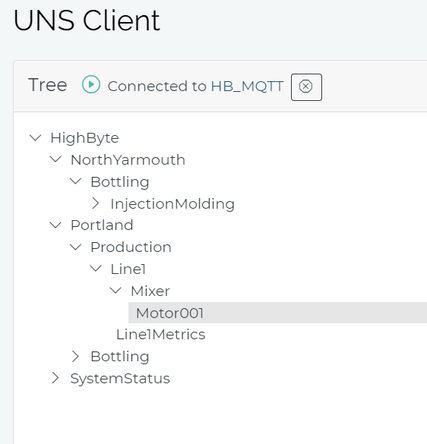
The strength of the UNS is that it makes data available for a wide range of use cases and personas within a company. However, unaltered source system data payloads typically don’t contain the data the consuming applications need, so determining which data must be grouped together requires source equipment and systems domain expertise. For example, if you need to monitor the power consumption of similar mixer motors in a plant for predictive maintenance purposes, you will need telemetry data, MES data, and CMMS data. You may also need to run some aggregations and calculations to get the actual required data set.
To go a level deeper, monitoring a mixer motor in a beverage plant may require the following telemetry data: motor state, speed, power consumption, and vibration. It may also require data from systems around the motor, like valve state and mixer tank fill percentage. You will also need data from the MES to understand the material being mixed and recipe, as well as the BatchID from the PLC to query the MaterialID from the MES. The CMMS system can provide the motor assetID and link it with manufacturer, age, and serial number. In this case, the analytic does not need every datapoint change all the time; it only requires a moving average and max value calculation on the speed, vibration, and current every 10 minutes.
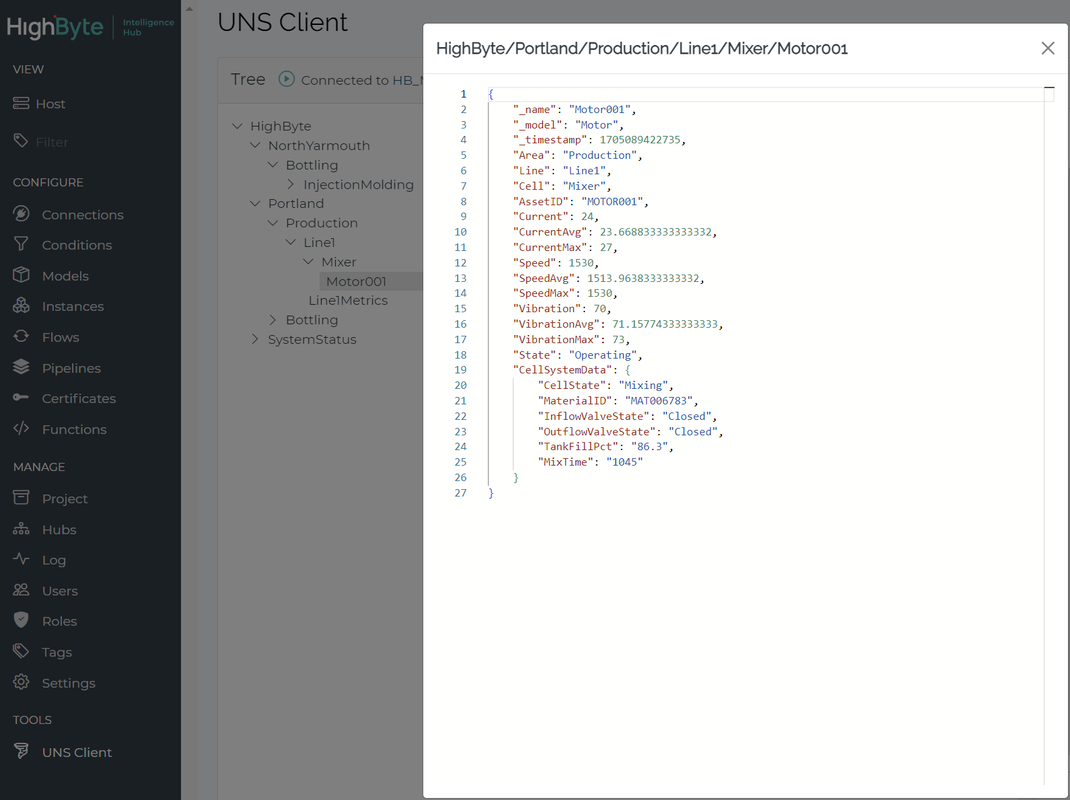
Rather than overloading the consuming application with large volumes of extraneous data, an Industrial DataOps solution can be used to easily create standardized payloads designed to satisfy the use cases by assembling the required data, contextualizing it as needed, and publishing updates at the required frequency. Here is a view of a standardized payload in HighByte Intelligence Hub an Industrial DataOps application that provides a complete toolset for building your UNS.
To go a level deeper, monitoring a mixer motor in a beverage plant may require the following telemetry data: motor state, speed, power consumption, and vibration. It may also require data from systems around the motor, like valve state and mixer tank fill percentage. You will also need data from the MES to understand the material being mixed and recipe, as well as the BatchID from the PLC to query the MaterialID from the MES. The CMMS system can provide the motor assetID and link it with manufacturer, age, and serial number. In this case, the analytic does not need every datapoint change all the time; it only requires a moving average and max value calculation on the speed, vibration, and current every 10 minutes.
Rather than overloading the consuming application with large volumes of extraneous data, an Industrial DataOps solution can be used to easily create standardized payloads designed to satisfy the use cases by assembling the required data, contextualizing it as needed, and publishing updates at the required frequency. Here is a view of a standardized payload in HighByte Intelligence Hub an Industrial DataOps application that provides a complete toolset for building your UNS.
Pause for definitions
As we proceed into more complex UNS payloads, here are a few definitions of key terms that you may find helpful.
Model: A model is simply a standardized definition of a data set containing related information. By standardizing the data set definition with a model, the same definition can be applied to similar objects. For example, a model could be defined for monitoring line productivity and might contain data from individual machines on the line and the MES. The same model can be adapted and reused to monitor similar lines. Best practices for creating using models include:
Instance: Models are applied to different objects as instances. The instance includes the mapping of the source system data to the model attribute name. For example, a Motor model might have an instance of Motor001 for a single specific motor in which all data mappings are managed.
Payload: A payload is each publish of the instance. A payload contains a set of name value pairs that are published at the same time, though depending on the definition, a payload may contain one or multiple values.
Model: A model is simply a standardized definition of a data set containing related information. By standardizing the data set definition with a model, the same definition can be applied to similar objects. For example, a model could be defined for monitoring line productivity and might contain data from individual machines on the line and the MES. The same model can be adapted and reused to monitor similar lines. Best practices for creating using models include:
- Define the model based on the use case.
- Models can combine data from multiple sources. Include the base telemetry data and any descriptive data or contextualization needed by the system and persona using it.
- Contextualization should include information or “edges” to support relating data sets from other systems. For instance, including the AssetID, manufacturer, and model number of an asset could be very helpful if analyzing maintenance data stored in a data lake.
- Define models based on frequency of publication. For example, data for analytics may be published at a standard rate of 1/sec, alarms may be published when they happen, and order data may be published each time a new order is completed or started. Analytics, alarms, and order data will have their own model but will be placed at the same level of the UNS hierarchy.
Instance: Models are applied to different objects as instances. The instance includes the mapping of the source system data to the model attribute name. For example, a Motor model might have an instance of Motor001 for a single specific motor in which all data mappings are managed.
Payload: A payload is each publish of the instance. A payload contains a set of name value pairs that are published at the same time, though depending on the definition, a payload may contain one or multiple values.
As a practice, assembling data payloads designed around use cases is vital for getting the most out of your unified namespace. The Intelligence Hub is an ideal tool for generating these payloads because you can create standard models for use cases and then apply them where appropriate in your UNS. Meaning, that once the model is defined for one mixer, the same model can be used for all mixer motors on all the lines and all the plants. HighByte Intelligence Hub easily enables the collation of data from multiple systems through no-code configuration—enabling a fast, repeatable, and maintainable approach to the UNS architecture.
Using the same data for different purposes
You’ll often find that a single source may provide data for multiple use cases. For example, a mixer might provide data on current, speed, and vibration to a predictive maintenance application, an Andon light and monitoring dashboard for the work cell, and an R&D team trying to track product cost. The Andon light is monitoring the cell state, tank fill percentage, and mixer operation, while the cell can generate alarms if the vibration or speed to current balance are not as expected. The cell dashboard includes the Andon status, quantity produced per shift, current work order, recipe, and customer. Meanwhile, the R&D team is monitoring the mixer’s power consumption to gain a more accurate understanding of product costs.
In this example, we have three different use cases: maintenance, production monitoring, and product costing and sustainability. Each requires unique payloads and contextualization, and each data set must be published to different topic locations in the UNS at different frequencies. The data for these three use cases must be sourced from many systems, including but not limited to an OPC server, MES, ERP, and CMMS. Despite these three use cases’ significant differences, they all have one thing in common: They require the mixer’s current, speed, and vibration data. The contextualization and frequency may differ significantly for each use case, but all three need the same data.
By using data models to package data into custom payloads, data consumers can more easily find and use the right data and provide the right data for analysis. The Intelligence Hub can be used to create models unique to each use case, delivering complex payloads that contain the mixer data with the right context and frequency to meet the needs of the predictive maintenance application, work cell, and R&D team.
In this example, we have three different use cases: maintenance, production monitoring, and product costing and sustainability. Each requires unique payloads and contextualization, and each data set must be published to different topic locations in the UNS at different frequencies. The data for these three use cases must be sourced from many systems, including but not limited to an OPC server, MES, ERP, and CMMS. Despite these three use cases’ significant differences, they all have one thing in common: They require the mixer’s current, speed, and vibration data. The contextualization and frequency may differ significantly for each use case, but all three need the same data.
By using data models to package data into custom payloads, data consumers can more easily find and use the right data and provide the right data for analysis. The Intelligence Hub can be used to create models unique to each use case, delivering complex payloads that contain the mixer data with the right context and frequency to meet the needs of the predictive maintenance application, work cell, and R&D team.
Wrap up
Use-case-based models aren’t just an added benefit for a UNS architecture; they are the key to accelerating UNS deployment and making the UNS useful for all consuming people and applications. With Models, Instances, Flows, and Pipelines, HighByte Intelligence Hub delivers the modeling capabilities needed to configure standardized payloads, and then replicate these payloads across all your similar assets, cells, lines, and sites.
If you’re ready to see what the Intelligence Hub can do firsthand, join our free trial program. Gain access to the latest release, product resources, and a HighByte team member to help guide you through your evaluation.
If you’re ready to see what the Intelligence Hub can do firsthand, join our free trial program. Gain access to the latest release, product resources, and a HighByte team member to help guide you through your evaluation.
