
Updated: 03/25/2020
Earlier this year, my colleague John Harrington wrote an article for Control Engineering that I think is worth sharing here as well. The article introduces a concept and process that gained popularity as early as the 1970s: Extract, Transform, Load—or more commonly known as ETL. An ETL system extracts data from the source systems, enforces data quality and consistency standards, conforms data so that separate sources can be used together, and finally delivers data in a presentation-ready format so that application developers can build applications and end users can make decisions (Kimball and Caserta, 2004). So why are we still talking about this acronym 50 years later? Because the unique challenges of working with industrial operations data demand a new look at an old concept.
The Background
By now, everyone has heard of Industry 4.0, Smart Manufacturing, and the Industrial Internet of Things. These concepts are used to describe the tremendous changes in operations technology brought on by a surge in underlying technologies including Cloud, big data, smart sensors, single board solid state computers, wireless networks, analytics, application development platforms, and mobile devices. Some of these technologies are not new but recent price drops and improved ease of use have dramatically increased their usage. These technologies are being combined with traditional operations technology like control systems and manufacturing execution systems to improve the operations and business functions of industrial companies by providing more data—and tools to leverage that data.
Many of these technologies were first developed for IT departments to interact with other business disciplines like Marketing, Sales, Logistics, and Finance. Given the vast amount of data in manufacturing and the ever-present desire to improve operations, these tools are being widely evaluated and adopted by IT. However, Operations teams looking to leverage industrial data face unique challenges around data integration that have slowed and increased the effort required to deploy such systems.
The IT industry solved its own data integration challenges by creating ETL solutions that integrated business systems with analytics systems. These solutions were designed to extract data from other systems and databases like Customer Relationship Management (CRM) and Enterprise Resource Planning (ERP), combine this data in an intermediate data store, and then transform the data by cleaning it, aligning it, and normalizing it. The data could then be loaded into the final data store to be utilized by analytics, trending, and search tools.
So why can’t these ETL solutions be used by Operations to prepare industrial data today? Simply put, industrial data coming off the controls system in a factory has different challenges than transactional data from business systems. Let’s look at these challenges in more depth.
Many of these technologies were first developed for IT departments to interact with other business disciplines like Marketing, Sales, Logistics, and Finance. Given the vast amount of data in manufacturing and the ever-present desire to improve operations, these tools are being widely evaluated and adopted by IT. However, Operations teams looking to leverage industrial data face unique challenges around data integration that have slowed and increased the effort required to deploy such systems.
The IT industry solved its own data integration challenges by creating ETL solutions that integrated business systems with analytics systems. These solutions were designed to extract data from other systems and databases like Customer Relationship Management (CRM) and Enterprise Resource Planning (ERP), combine this data in an intermediate data store, and then transform the data by cleaning it, aligning it, and normalizing it. The data could then be loaded into the final data store to be utilized by analytics, trending, and search tools.
So why can’t these ETL solutions be used by Operations to prepare industrial data today? Simply put, industrial data coming off the controls system in a factory has different challenges than transactional data from business systems. Let’s look at these challenges in more depth.
Phase One: Extract
Operational data is not all stored in a database as transactions cleanly waiting to be extracted. Rather, it is available in real time from PLCs, machine controllers, SCADA systems, and/or time series databases throughout the factory. So instead of extracting data from a handful of large databases, data must be streamed from hundreds of devices and systems.
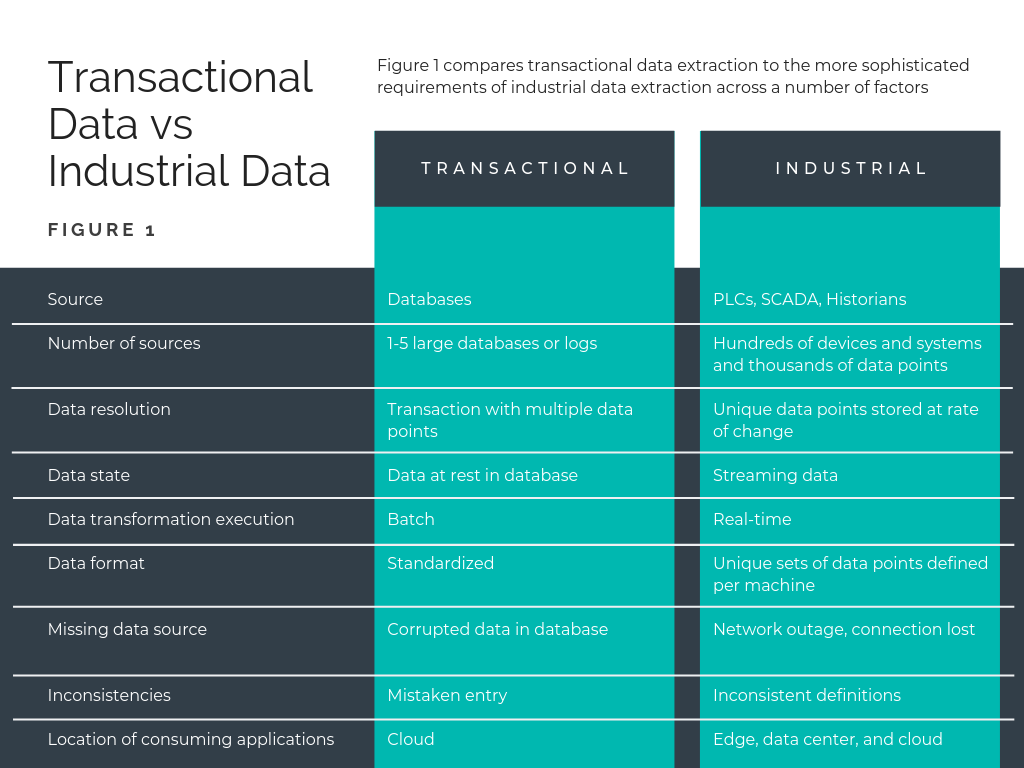
Transaction processing systems store complete records for each transaction, but in factories, process data is not captured as “transactions". A high-volume discrete manufacturer cannot store the complete data set for each component that comes off the line, and a batch manufacturer often needs to store more than a single value per batch. Industrial data must be collected at a high rate to catch any anomalies and then stored at different rates based on the use case. This makes extraction much more complex (see Figure 1).
Transaction processing systems store complete records for each transaction, but in factories, process data is not captured as “transactions". A high-volume discrete manufacturer cannot store the complete data set for each component that comes off the line, and a batch manufacturer often needs to store more than a single value per batch. Industrial data must be collected at a high rate to catch any anomalies and then stored at different rates based on the use case. This makes extraction much more complex (see Figure 1).
Phase Two: Transform
Data transformation on operational data requires more of a conditioning than a transformation.
Operational data storage often happens periodically—every second, minute, or hour. The stored data may be an actual value like the quantity produced, or it could be statistical calculations of the raw data like the average, min, and max temperature values checked every second but recorded every hour.
Data points on Programmable Logic Controllers (PLCs) generally have an address or name and a value. However, these data points only provide a process or controls-centric view of the data. There are no descriptions, units of measure, operating ranges, or other descriptive information. This creates challenges as industrial data is used outside of the controls environment for machine maintenance, process optimization, quality, and traceability. In these cases, the data must be analyzed and aligned by machine for machine maintenance, by process for process optimizations, and by product for quality and traceability. The required data is often available but must be correlated appropriately and sometimes transposed into a usable format.
Furthermore, typical factories have machinery from many different vendors and equipment that has been purchased over a 10 to 30-year timespan. This variety in machinery results in a wide variety of available data. Some data points may simply have different names while others may have different units of measure or different measurements entirely. For analytics, trending, or any sort of data analysis to be possible, the data points must be standardized, normalized, and in some cases calculated based on component measures.
Finally, analytics data is generally not as critical as controls data, so companies have started to use lower cost sensors to collect data for non-critical analysis. However, these sensors can fail or drift so redundant sensors with external data validation is important to ensure good data is being stored.
Operational data storage often happens periodically—every second, minute, or hour. The stored data may be an actual value like the quantity produced, or it could be statistical calculations of the raw data like the average, min, and max temperature values checked every second but recorded every hour.
Data points on Programmable Logic Controllers (PLCs) generally have an address or name and a value. However, these data points only provide a process or controls-centric view of the data. There are no descriptions, units of measure, operating ranges, or other descriptive information. This creates challenges as industrial data is used outside of the controls environment for machine maintenance, process optimization, quality, and traceability. In these cases, the data must be analyzed and aligned by machine for machine maintenance, by process for process optimizations, and by product for quality and traceability. The required data is often available but must be correlated appropriately and sometimes transposed into a usable format.
Furthermore, typical factories have machinery from many different vendors and equipment that has been purchased over a 10 to 30-year timespan. This variety in machinery results in a wide variety of available data. Some data points may simply have different names while others may have different units of measure or different measurements entirely. For analytics, trending, or any sort of data analysis to be possible, the data points must be standardized, normalized, and in some cases calculated based on component measures.
Finally, analytics data is generally not as critical as controls data, so companies have started to use lower cost sensors to collect data for non-critical analysis. However, these sensors can fail or drift so redundant sensors with external data validation is important to ensure good data is being stored.
Phase 3: Load
With the introduction of these new technologies, there are also many more business users who want access to high resolution, automated data feeds from operations. They use unique systems to analyze and make use of the data and have differing requirements. These business users vary by company but often include manufacturing operations, maintenance, quality, and value engineering. Additionally, machine vendors have started to sell service contracts with requirements for their real-time data collection.
Managing the delivery of data is important. There are security risks as well as significant costs associated with storing incorrect, corrupt, or useless data.
Industrial data extraction and transformation must happen close to the production machinery. This allows the data to be used by local edge analytics, sent to on-premises data centers, or sent to the Cloud based on the most efficient use.
Managing the delivery of data is important. There are security risks as well as significant costs associated with storing incorrect, corrupt, or useless data.
Industrial data extraction and transformation must happen close to the production machinery. This allows the data to be used by local edge analytics, sent to on-premises data centers, or sent to the Cloud based on the most efficient use.
Wrap Up
The need to extract, transform, and load operational data is as great as—if not greater than—the need for ETL in typical IT business system integration. Yet industrial ETL has unique and sophisticated requirements. This demands a rethink of data architecture and the creation of new industrial data infrastructure solutions. These new industrial data infrastructure solutions must simplify and streamline data integrations for industrial companies to achieve the value expected from Industry 4.0, Smart Manufacturing, and the Industrial Internet of Things.
If these challenges described above resonate for you and your operations, we welcome you to learn more about HighByte Intelligence Hub and participate in our free trial program. HighByte Intelligence Hub provides industrial companies with an off-the-shelf ETL solution to accelerate and scale the usage of operational data throughout the extended enterprise by contextualizing, standardizing, and securing this valuable information. HighByte Intelligence Hub is able to run at the Edge, scale from embedded to server-grade computing platforms, connect devices and applications via OPC UA and MQTT, process streaming data through standard models, and deliver contextualized and correlated information to the applications that require it.
If these challenges described above resonate for you and your operations, we welcome you to learn more about HighByte Intelligence Hub and participate in our free trial program. HighByte Intelligence Hub provides industrial companies with an off-the-shelf ETL solution to accelerate and scale the usage of operational data throughout the extended enterprise by contextualizing, standardizing, and securing this valuable information. HighByte Intelligence Hub is able to run at the Edge, scale from embedded to server-grade computing platforms, connect devices and applications via OPC UA and MQTT, process streaming data through standard models, and deliver contextualized and correlated information to the applications that require it.
